Data Structure
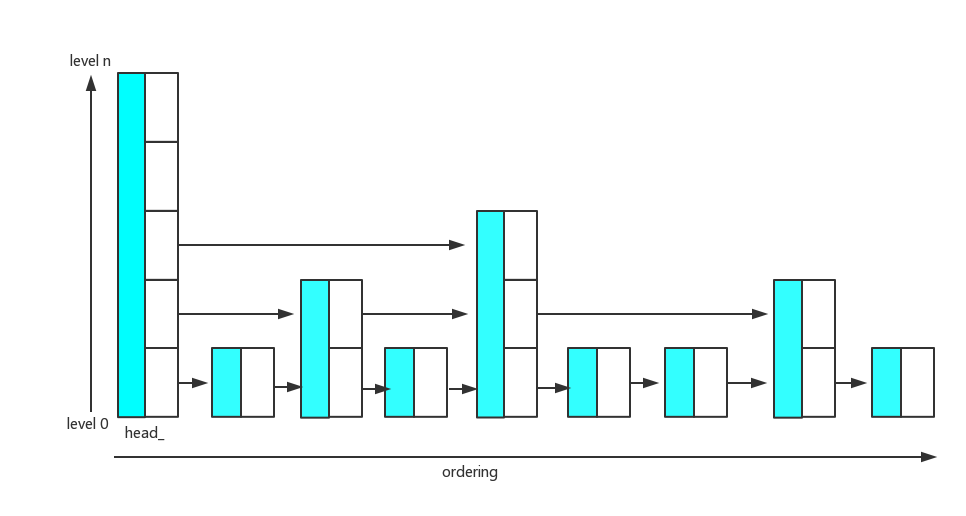
leveldb memtable需要满足以下几种要求:
- get 足够快
- write 足够快
- iterator 足够快 (compact to sst file by ordering)
那么skiplist作为一个同时兼顾list和tree属性的data structure, 是非常好的选择。
Concurrency
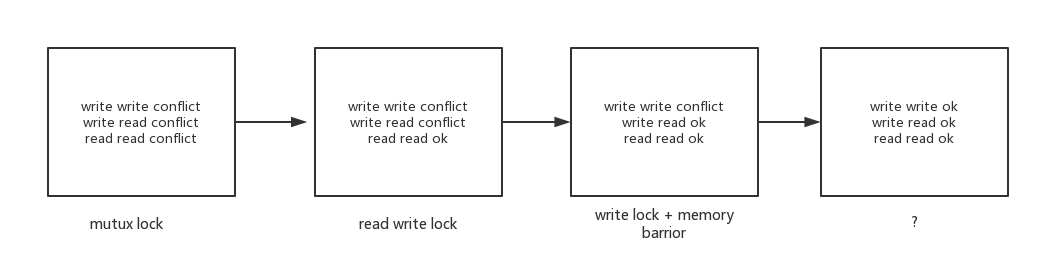
leveldb skiplist 通过采用write lock和memory barrier的方式, 保证读读, 读写操作不会冲突, 提高并发能力。
Implementation Details
skiplist doc:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// Thread safety
// -------------
//
// Writes require external synchronization, most likely a mutex.
// Reads require a guarantee that the SkipList will not be destroyed
// while the read is in progress. Apart from that, reads progress
// without any internal locking or synchronization.
//
// Invariants:
//
// (1) Allocated nodes are never deleted until the SkipList is
// destroyed. This is trivially guaranteed by the code since we
// never delete any skip list nodes.
//
// (2) The contents of a Node except for the next/prev pointers are
// immutable after the Node has been linked into the SkipList.
// Only Insert() modifies the list, and it is careful to initialize
// a node and use release-stores to publish the nodes in one or
// more lists.
//
// ... prev vs. next pointer ordering ...
主要以下几点:
- 写操作需要外部同步, 比如mutex
- 读操作要保证在读的时候, skiplist不要destroy, 比如reference count, 读操作内部不会用到锁或者其他同步器
- skiplist内部分配的node是不会被删除的, 除了skiplist被destroy外
- node的内容除了next/pre指针外, 其他是不会改变的, 只有Insert()会修改list,Insert()巧妙的初始化node, 并通过release-stores(内存屏障)把node加到skiplist中, 保证对reads的可见性。
- 不难看出, put, delete, update等方法都是通过insert new entry实现的。
Node
1 | // Implementation details follow |
Node的提供了两套set/get next方法, 一种是普通的, 另一种是memory barrier的, 后一种可以保证数据的可见性。这里简单提一下memory barrier, 语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。
Node内部的数据, 除了需要保存key外, 还有一个长为1的指针数组,用于存储level 0的next node的地址, 那其他level的呢? 在node init时, 多申请出height-1的地址空间, 用于存储其他level的地址。这里如果我设计,要么用linklist,要么设置一个长度为最大长度的数组, 要么只存放一个数组指针, 这个方法我估计想不到。
Insert()
1 | template<typename Key, class Comparator> |
memory barrier 使用难度比lock要高的多, 需要考虑的情况更为复杂, 就如瓜帅的传控足球, 磨练时可能意外颇多,一旦炉火纯青,就砍瓜切菜一般。
Iterator
在leveldb里, Iterator是一个非常重要的概念, 包括block, table, memtable等很多都提供了Iterator, Iterator是访问这些数据结构内部数据的重要工具。SkipList<Key,Comparator>::Iterator::Seek - Advance to the first entry with a key >= target, 这里并没有seek等确切相等的entry, 外部实现(memtable)get时, 会处理这种不相等的情况。
others
除了search时, nodo的next要使用具有memory barrier的, 其他实现细节就比较简单了
总结
外部与leveldb其他部分相关的insert(put update delete)的设计, 内部lock(虽然外部同步,但是与内存设计相关), memory barrier, 存储细节的考虑, 几百行代码的skiplist, 需要细细品味的东西太多了。